Uno dei casi in cui si presenta questa eccezione è in un contesto Spring. Siamo stati bravi, abbiamo usato l’interfaccia JpaRepository ma ci siamo dimenticati di aggiungere le annotation Entity e Table per indicare che la classe di riferimento mappa una tabella del db.
Tutti gli articoli di admin
ECCEZIONE – THE PORT MAY ALREADY BE IN USE
Capita che la porta su cui lanciamo il nostro servizio sià già occupata e pertanto riceviamo una eccezione del tipo The Tomcat connector configured to listen on port failed to start. The port may already be in use or the connector may be misconfigured.
La prima soluzione è cambiare la porta che stiamo utilizzando agendo sul file di configurazione, la seconda soluzione è individuare il servizio che sta occupando la nostra parte e stopparlo.
In ambiente window per risolvere il problema occorre usare i comandi netstat per inviduare il processo e taskkill per eliminarlo
|
1 |
netstat -ao | find "10001" |
con questo comando elenchiamo tutti i processi e filtriamo quello che occupa la porta 10001
|
1 |
TCP 0.0.0.0:10001 <nome> LISTENING 9344 |
L’ultimo parametro indica il PID del processo incriminato e per eliminarlo usiamo taskskill
|
1 2 |
Taskkill /PID 9344 /F |
VUFIND – TUTORIAL 10 – PERFORMANCE
Al crescere dell’indice da gestire possiamo notare in Vufind un decadime nto delle prestazioni fino al suo completo blocco. La piattaforma presenta più componenti pertanto gli interventi di tuning coinvolgono sia la componente php/apache che gestisce il livello di presentazione che la componente java che gestisce l’indice della nostra biblioteca. Per poter monitorare le performance è buona norma mettere in piedi una procedura di stress test che simuli il carico di produzione, per questo vufind consiglia di usare jmeter o WCAT( Web Capacity Analysis Tool) di Microsoft. Per esigenze ho usato WCAT che, configurato correttamente, permette di simulare n accessi concorrenti con le query più disparati al fine di valutare il comportamento della nostra piattoforma sotto carico. A questo punto scarichiamo WCAT versione 32 bit o 64 bit e configuriamo il nostro client definendo lo scenario tramite un apposito file e il numero di utenti da simulare.
Esempio di file scenario.txt che simula una ricerca libera
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
scenario { warmup = 1; duration = 120; cooldown = 20; transaction { id = "onesearch"; weight = 1000; request { url = "/vufind/Search/Results?lookfor=" + rand("1", "1000000"); secure = false; } } } |
E’ possibile aggiungere altre transazioni per simulare altre ricerche.
Esempio di file settings.txt che simula 30 utenti
|
1 2 3 4 |
settings { virtualclients = 30; } |
A questo punto potete aprire 2 shell cmd per avviare il testing e ipotizzando che il nostro vufind giri sul nostro localhost scriveremo
|
1 |
wcctl -s localhost -t scenario.txt -f settings.txt -c 1 |
|
1 |
wcclient localhost |
A questo punto il client incomincia ad avviare un utente dopo l’altro e a simulare le chiamate configurate. A fine esecuzione sarà possibile consultare il report che indicherà quante richieste sono state effettuate e quante di esse hanno avuto esito positivo. A questo punto per aumentare le prestazioni, se i tempi di risposta non sono soddisfacenti, occorre agire sulla RAM del solr, sul numero di CORE e il tipo di Garbage Collection del nostro server. A questo punto ci viene in soccorso la doc ufficiale di vufind che riporta questo schema di prestazioni per un indice da 8,8 milioni di record:
| CPU Cores (2.7GHz) | Memory (GB) | Garbage Collection | Fresh (Req/s) | Cached (Req/s) |
|---|---|---|---|---|
| 24 | 30 | ConcMarkSweepGC | 327.9 | 705.9 |
| 24 | 30 | G1GC | 93.3 | 167.5 |
| 24 | 30 | ParallelGC | 320.6 | 701.2 |
| 24 | 8 | ConcMarkSweepGC | 205.5 | 780.0 |
| 24 | 8 | G1GC | 64.0 | 147.2 |
| 24 | 8 | ParallelGC | 250.7 | 788.3 |
| 2 | 30 | ConcMarkSweepGC | 81.1 | 161.4 |
| 2 | 30 | G1GC | 65.6 | 123.9 |
| 2 | 30 | ParallelGC | 75.6 | 220.9 |
Il report evidenzia la differenza di prestazione tra le ricerche nuove e le ricerche mantenute in cache.
TUTORIAL – CONFIGURARE CLIENT PER CANTALOUPE IMAGE SERVER
L’articolo illustra come configurare un client che si colleghi a Cantaloupe. Una volta configurato Cantaloupe occorre realizzare un client per poter usare i servizi esposti e mostrare le derivate richieste. Per poter usare i servizi andrebbe realizzato un rest client, ma il mercato già offre dei client in javascript che permettono di vedere l’immagine con comodo funzioni di zoom,
La prima scelta è leaflet che implementa la gestione di una mappa interattiva. Per poterla usare è sufficiente realizzare una pagina html che chiami la pagina la pagina info.json dell’immagine desiderata, come illustrato sotto
|
1 2 3 4 5 6 7 8 9 10 11 |
<body> <div id="map"></div> <script> var map = L.map('map', { center: [0, 0], crs: L.CRS.Simple, zoom: 0, }) L.tileLayer.iiif('http://localhost:8182/iiif/2/0001_2.jpg/info.json').addTo(map); </script> </body> |
se avete operato bene chiamando la pagina html vedremo la nostra immagine con le funzioni di zoom attive.
Un altro client utilizzabile è Openseadragon , che aumenta il numero di funzioni a disposizione e presenta opzioni per gestire tutti i casi d’uso comuni. Se la banda non è un problema è possibile integrare l’immagine completa e demandare al client la gestione dello zoom
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<body> <div id="openseadragon1"></div> <ul class="pgwSlideshow"> </ul> <script src="openseadragon.min.js"></script> <script type="text/javascript"> OpenSeadragon({ id: "openseadragon1", prefixUrl: "images/", immediateRender: true, showNavigator: true, preserveViewport: true, timeout: 60000, tileSources: { type: 'image', url: 'http://localhost:8182/iiif/2/0001_2.jpg/full/full/0/default.jpg' } }); </script> </body> |
In questo modo scarichiamo il carico computazionale sul client e Cantaloupe non effettua elaborazioni, mentre se vogliamo sfruttare la potenza di Cantaloupe il codice da usare è il seguente
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<body> <div id="openseadragon1"></div> <ul class="pgwSlideshow"> </ul> <script src="openseadragon.min.js"></script> <script type="text/javascript"> OpenSeadragon({ id: "openseadragon1", prefixUrl: "images/", immediateRender: true, showNavigator: true, preserveViewport: true, timeout: 60000, tileSources: 'http://localhost:8182/iiif/2/0001_5.jpg/info.json' }); </script> </body> |
TUTORIAL – CANTALOUPE IMAGE SERVER
Per esigenze lavorative ho dovuto utilizzare un image server, capace di effettuare trasformazione di immagini a runtime per adattare le immagini a qualsiasi dispositivo. La scelta è caduta su Cantaloupe, un image server scritto in java compliant con le API IIIF, che definiscono un interfaccia di servizi da invocare per effettuare le principali operazioni sulle immagini. Installare e avviare Cantaloupe è molto semplice, è sufficiente scaricare dalla homepage il file zip contenente i binari, scompattare e lanciare l’eseguibile non prima di aver creato il file di configurazione nella stessa cartella. Per la mia installazione ho usato Cantaloupe v. 3.3.5 e per avviare il server ho usato la direttiva
|
1 |
java -Dcantaloupe.config=cantaloupe.properties -Xmx2g -jar Cantaloupe-3.3.5.war |
La configurazione di default prevede che il server stia in ascolto sulla porta 8182, pertanto se avete fatto tutto correttamente accedendo al link http://localhost:8182/ comparirà la nostra home page, ovvero una bella fetta di cantalupo indicante la versione corrente.

A questo punto attiviamo il pannello di amministrazione. Per farlo accediamo al file di configurazione e attiviamo tramite la sezione
|
1 2 3 4 |
# Enables the Control Panel, at /admin. admin.enabled = true # Password to access the Control Panel. (The username is "admin".) admin.password = admin |
Nel mio caso ho scelto admin come password, riavviamo e accediamo al link http://localhost:8182/admin, inseriamo i dati accesso ed ecco il nostro pannello

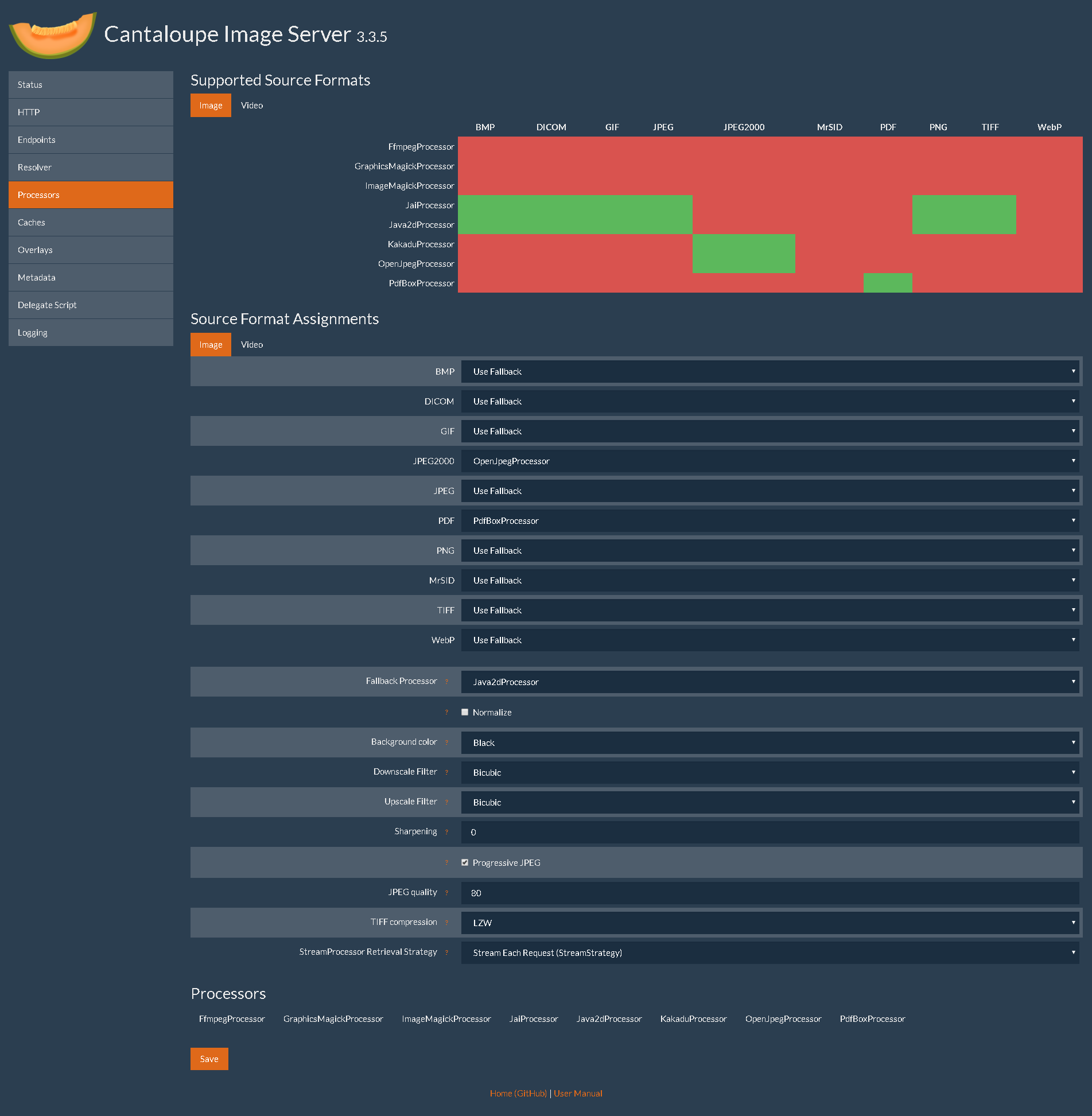
Per le informazioni sulle varie funzionalità a disposizione rimando al manuale, soffermiaci su 2 schede in particolare: resolvers e processors. I processors sono gli oggetti che effettuano le trasformazioni sulle immagini e sono legate ai formati che dobbiamo gestire e gli standard supportati sono rappresentati nella scheda in una comodo tabella. La configurazione di default prevede l’uso di java2dprocessor, ma siamo liberi di fare quello che vogliamo.
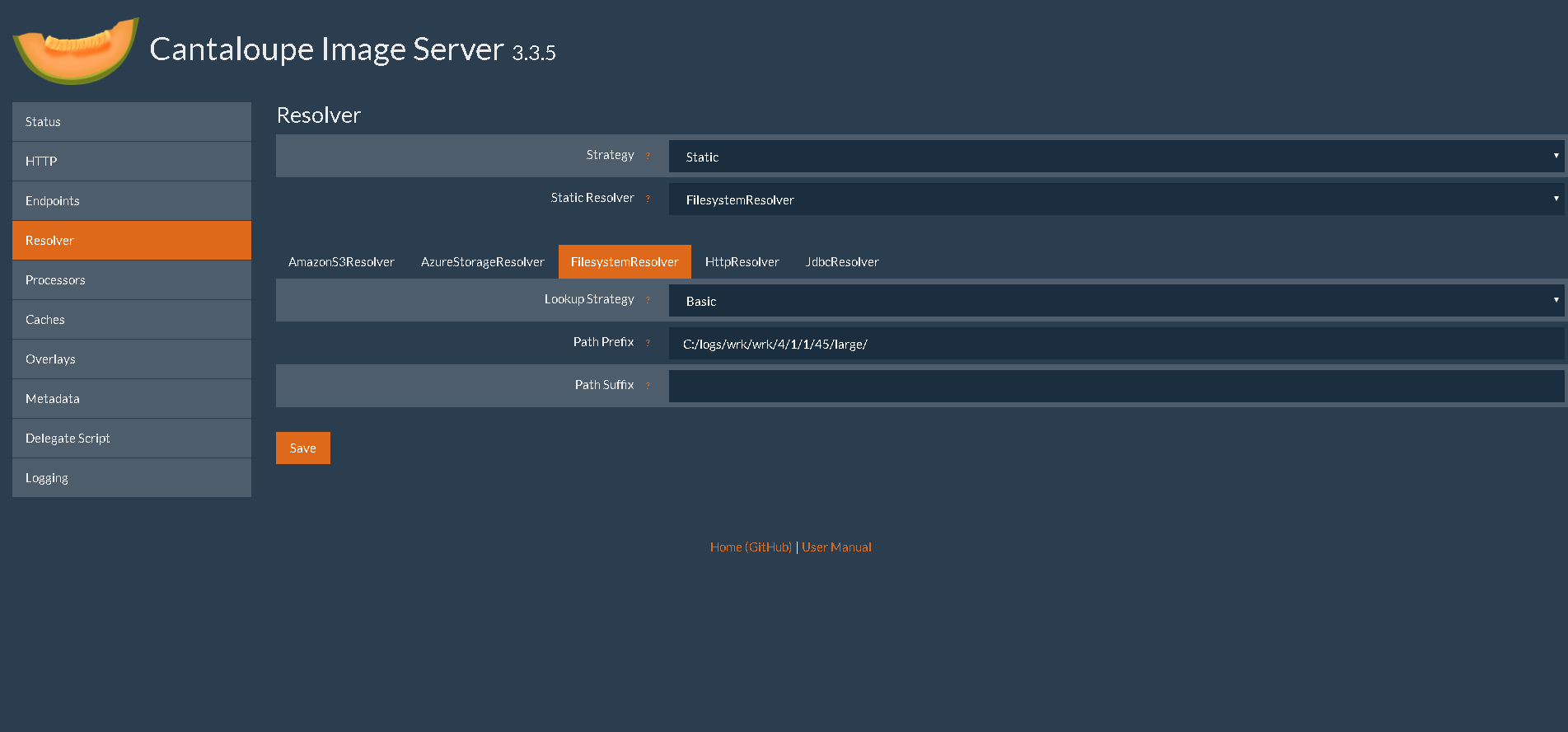
I resolvers sono gli oggetti che a partire da un identificativo alfanumerico sono in grado di recuperare l’immagini. Sono presenti vari tipi, ma quello di default è il FilesystemResolver che a partire da una directory recupera l’immagine grazie al nome
Se voglio ottenere i metadati di una immagine occorre invocare l’url
|
1 |
http://localhost:8182/iiif/2/0001_2.jpg/info.json |
dove 0001_2.jpg è il nome del file. Con tale direttiva ottengo i metadati del file in formato json
|
1 |
{"@context":"http://iiif.io/api/image/2/context.json","@id":"http://localhost:8182/iiif/2/0001_2.jpg","protocol":"http://iiif.io/api/image","width":9638,"height":10783,"sizes":[{"width":75,"height":84},{"width":151,"height":168},{"width":301,"height":337},{"width":602,"height":674},{"width":1205,"height":1348},{"width":2410,"height":2696},{"width":4819,"height":5392}],"tiles":[{"width":1205,"height":1348,"scaleFactors":[1,2,4,8,16,32,64,128]}],"profile":["http://iiif.io/api/image/2/level2.json",{"formats":["jpg","tif","gif","png"],"maxArea":400000000,"qualities":["bitonal","default","gray","color"],"supports":["regionByPx","sizeByW","sizeByWhListed","cors","regionSquare","sizeByDistortedWh","sizeAboveFull","canonicalLinkHeader","sizeByConfinedWh","sizeByPct","jsonldMediaType","regionByPct","rotationArbitrary","sizeByH","baseUriRedirect","rotationBy90s","profileLinkHeader","sizeByForcedWh","sizeByWh","mirroring"]}]} |
Per ottenere l’immagine originale il link da invocare è il seguente
|
1 |
http://localhost:8182/iiif/2/0001_2.jpg/full/full/0/default.jpg |
Per ottenere le varie derivate occorre variare i parametri che seguono l’identificativo del file nel rispetto delle api IIIF, per maggiori dettagli leggete le specifiche disponibili qui
ECCEZIONI JAVA – org.springframework.jdbc.BadSqlGrammarException
Ultimamente mi sono imbattuto in un problema interessante legato ai driver Oracle: una funzione rilasciata non funzionava nel nuovo ambiente e dava l’eccezione BadSqlGrammarException e più precisamente .
|
1 |
org.springframework.jdbc.BadSqlGrammarException: CallableStatementCallback; bad SQL grammar [{? = call GETREPORTGENERALE(?, ?, ?, ?)}]; |
Comincio l’analisi del problema e la segnalazione fa pensare che l’applicativo stia invocando in modo errato la function, che effettivamente in ingresso riceve 5 parametri e non 4 come fa vedere il log. Rigenero il war pensando che sia stata installata una versione diversa ma il problema persiste. A questo punto penso che il problema possa essere lato db, pertanto rigenero gli script sql e vengono reinstallati nell’ambiente di riferimento. Niente da fare. Mi accorgo che la versione Oracle tra i 2 ambienti è differente, ma questo non dovrebbe spiegare l’errore. Non mi resta che controllare i 2 ambienti, in questo caso un tomcat 7 e mi accordo che i 2 ambienti presentano versioni di driver oracle differenti. Il cliente aveva effettuato l’aggiornamento della versione Oracle alla 12 e di conseguenza aveva aggiornato la versione del driver Oracle, passando dalla 10 alla 12. Ecco individuato il problema, la chiamata falliva se fatta con il nuovo driver. La chiamata sfrutta la classe SimpleJdbcCall offerta da Spring
|
1 2 3 |
SimpleJdbcCall jdbcCall = new SimpleJdbcCall(getJdbcTemplate()). withFunctionName("getReportGenerale"). returningResultSet("reportGenerali", new ReportMapper()); |
Per risolvere il problema ho dovuto modificare il sorgente, rinunciare alla SimpleJdbcCall e utilizzare la classica CallableStatement
|
1 2 |
CallableStatement prepareCall = getConnection().prepareCall(getReportGenerale); prepareCall.registerOutParameter(1,OracleTypes.CURSOR); |
TUTORIAL GWT – COME DEBUGGARE USANDO IL SUPERDEV
Con l’introduzione del superdev mode non è più possibile usare il debug nel nostro IDE come siamo stati abituati. Per poter usare il debug occorre installare il plugin SDBG disponibile qui.
Una volta installato il plugin avviamo il nostro progetto tramite il superdev mode e una volta che il sistema è correttamente avviato, creiamo una configurazione Chrome che carichi la hosted page e su questa avviamo il debug.
Se abbiamo fatto tutto correttamente verranno attivati i breakpoint selezionati in Eclipse, e sarà anche possibile usare il debug all’interno di Chrome, usando il Chrome DevTools JavaScript debugger.
TUTORIAL SPRING BOOT – CAMBIARE PORTA
TUTORIAL JHIPSTER – PRIMI PASSI
Durante la fase di scouting per valutare nuovi framework e nuove librerie mi sono imbattuto in JHIPSTER. Si tratta di una piattaforma di sviluppo che consente di generare una applicazione con quello che gli autori reputano il meglio che il panorama offre. Nel momento in cui scrivo la versione è la 4.14.0, che permette di realizzare una webapp basata su Spring Boot 1.5 e Angular 5, mentre la versione 5, già annunciata, promette il passaggio a Spring Boot 2 e l’introduzione di React per il client e la rimozione di Angular JS. JHIPSTER ha vinto il Duke’s Choice Award 2017 e si è classificato terzo al JAX Innovation award nella categoria maggior innovazione per l’ecosistema JAVA.
Avvicinarsi a JHIPSTER ci da il vantaggio di vedere concentrato il top delle tecnologie a disposizione del mondo JAVA e ci da l’opportunità di assemblarle riducendo al minimo i tempi di creazione della applicazione. Partiamo subito e tiriamo su il nostro primo progetto. Per usare JHIPSTER abbiamo sei approcci possibili:
- JHipster Online è un tool online che ti guida nella creazione dell’app, va bene come prova ma allo stato attuale non consente di gestire modifiche successive
- “Locale con YARN” è la modalità suggerita dagli autori. Si basa su YARN , che è il package manager sviluppato da facebook basato su NPM.
- “Locale con NPM” è identica alla precedente, ma usa NPM il package manager di Node.js.
- “Installazione tramite package manager” è ancora in beta
- “Box Vagrant” è disponibile una macchina virtuale che contiene tutti gli strumenti necessari.
- “Docker” è disponibile un container docker contenente gli strumenti necessari
Usiamo la modalità consigliata e seguiamo i seguenti passi:
- Installiamo Java 8
- Installiamo Node.js
- Installiamo Yarn
- installiamo Yeoman tramite il comando: yarn global add yo. Yeoman è un tool che consente di creare la struttura base di una app.
- installiamo JHipster tramite il comando: yarn global add generator-jhipster
Seguendo questi step siamo in grado di creare la nostra app con front-end Angular, qualora volessimo usare AngularJS dobbiamo aggiungere altri due step:
- Installare Bower: yarn global add bower. Bower è un package manager rimasto in maintenance, ormai sostituito da YARN e WEBPACK.
- Installare Gulp: yarn global add gulp-cli. Gulp è un task manager.
A questo punto non resta che creare la nostra prima applicazione. Creiamo una directory e al suo interno lanciamo il comando: jhipster
E qui inizia il bello. Jhipster ci interroga sulle caratteristiche che vogliamo e il gioco è fatto, alla fine abbiamo una applicazione correttamente funzionante, da poter importare nel nostro editor preferito.
Per vederla funzionante lanciate il comando mvnw, che tirerà su il progetto su porta 8080.
TUTORIAL GWT – CREARE UNA WEBAPP CON GWT 2.8
Da tempo pensavo di aggiornare i componenti che uso in ufficio e ho deciso di partire da GWT. Nel momento in cui scrivo l’ultima versione è la 2.8.2. Mi piace GWT, mi piace l’idea di lavorare solo in java e xml e non dovermi preoccupare delle librerie javascript, durante la generazione del war sarà GWT a trasformare le classi java in unico file javascript che sarà incluso all’interno del mio progetto.
Andiamo sul sito http://www.gwtproject.org e partiamo dall’analisi dei requisiti di sistema. La nuova versione ha una dipendenza minima di JDK 1.8, Google ci avvisa che il sistema compila correttamente su JDK 1.7 ma che la modalità in devmode presenta malfunzioni. L’IDE di riferimento è Eclipse, nel momento in cui scrivo sto usando la versione Oxygen. Su questa installiamo il GWT Eclipse plugin e possiamo iniziare.
A questo punto avete 2 possibilità:
- usare il wizard che vi tira su il progetto con la sua alberatura e lo rende già eseguibile .
- Integrare maven, integrare il plugin disponibile e creare il nostro progetto a partire da un archetipo .
L’opzione 1 è quella più rapida, selezionando i dati di esempio, ci permette di avere subito il progetto operativo e poterlo lanciare tramite una delle seguenti opzioni :
- GWT Development Mode (Avvia un server in ascolto delle richieste del client. Se tutto è ok vai all’indirizzo http://127.0.0.1:9876/ per vedere il server attivo. A questo punto occorre configurare un qualsiasi server per caricare il contesto web )
- GWT Development Mode with jetty (Avvia il code server ed un jetty server con il client attivo. A questo punto se tutto è ok accedete alla pagina http://127.0.0.1:8888/ e vedrete la home page dell’applicativo. Rispetto al punto precedente, abbiamo già il web server pronto.)
- GWT Legacy Development Mode with jetty (Avvia l’applicativo usando un processo OOHPM. Tale processo non è più supportato dai moderni browser. Infatti è possibile vederlo attivo solo su una vecchia versione di firefox su cui va installato il google web toolkit developer plugin).
Il plugin ha creato la directory war e 3 package per i sorgenti: client, server e shared. Ad ogni package corrisponde una visibilità ed un comportamento diverso. Tutti i sorgenti saranno compilati in .class sotto la WEB-INF, i sorgenti del package server sono visibile solo alla parte server del progetto e non al frontend, i sorgenti della parte client verranno trasformati in javascript, pertanto alcune classi non saranno disponibili perchè non supportate da Javascript (es. Calendar o String.format), i sorgenti del package shared saranno visibili sia al frontend che al backend.
Nota dolente di questo approccio è che il wizard fallisce qualora si chiede la creazione del progetto con struttura maven. Appena generato il progetto indica errori di compilazione e questo non è bello, visto che ha fatto tutto da solo.
![]()
Aprendo la console è possibile far partire il progetto usando la direttiva mvn war:exploded gwt:devmode, mentre in eclipse occorre configurare il progetto per correggere gli errori. Per correggere l’errore in Eclipse lanciate la direttiva mvn eclipse:eclipse e fate il refresh in Eclipse del progetto, in questo modo dovrete soltanto da aggiungere la dipendenza da GWT tramite IDE e tutto dovrebbe riattivarsi.
Adesso veniamo al punto 2, con Maven posso partire da un archetipo che mi mette a disposizione tutte le librerie che mi servono con minimo sforzo. Devo realizzare una webapp che esponga un front-end gwt e dei servizi rest per l’accesso alla base dati. Parto quindi dall’archetipo minimo previsto per gwt e a questo aggiungo spring web per la gestione dei servizi rest e restyGWT per integrarli in modo più rapido. Voglio rendere al minimo l’uso delle chiamate RPC. In questo modo potrò disaccoppiare i sistemi e un domani eventualmente sostituire GWT con un altro frontend, senza dover toccare il backend. Impostato il progetto lo facciamo partire con la direttiva e il gioco è fatto
|
1 |
mvn war:exploded gwt:devmode |
Per riassumere trovate il pom del progetto con le dipendenze già pronte.
Buon divertimento